
前缀和
什么问题适合用前缀和
适用于快速、频繁地计算一个索引区间内的元素之和
前缀和算法框架
一维
每次累加前缀,当前元素指的是0-i的前缀和
注:从1开始是为了避免边界另外讨论,sum_list大小为原数组大小+1。填充的边界为0
适用于快速、频繁地计算一个索引区间内的元素之和
每次累加前缀,当前元素指的是0-i的前缀和
注:从1开始是为了避免边界另外讨论,sum_list大小为原数组大小+1。填充的边界为0
对于连续子序列问题,可以使用滑动窗口。例如按要求得到最长/短的序列
int low = 0, high = 0;
while (high < nums.size()) {
// 增大窗口
window.addLast(nums[high]);
high++;
while (window needs shrink) {
// 缩小窗口
window.removeFirst(nums[low]);
low++;
}
}滑动窗口方法需要考虑两个问题
通过 one-hot 编码来表示单词有两个缺陷:
所以基于此提出了词嵌入技术。将一个维数为所有词的数量的高维空间(one-hot 形式表示的词)“嵌入”到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量
word2vec 是训练词嵌入的训练方法,其输入为 one-hot 编码,通过一个隐藏层输出单词(CBOW)或者上下文(Skip-gram)的one-hot 编码。其模型结构为 y=softmax(wx+b)

初始化流程主要包括从磁盘中加在持久化配置,将自己的状态设为 Follower
init:从磁盘中加在持久化配置,将自己的状态设为 Follower
becomeFollower:状态机切换为 Follower,执行 Follower 的处理流程
在MySQL中,视图是一种虚拟表,它是由一个或多个基本表的行或列组成的。视图并不实际存储数据,而是根据定义的 select 语句动态生成结果集。视图可以简化复杂的查询操作,提高查询效率,同时也可以保护数据的安全性,隐藏敏感数据。
执行过程类似于 select 语句,流程如下
MySQL 的数据是存储在磁盘里的,但每次访问磁盘开销过大。为此,Innodb 存储引擎设计了一个缓冲池(Buffer Pool),当数据从磁盘中取出后,缓存到Buffer Pool中,下次查询同样的数据的时候,直接从内存中读取,来提高数据库的读写性能。
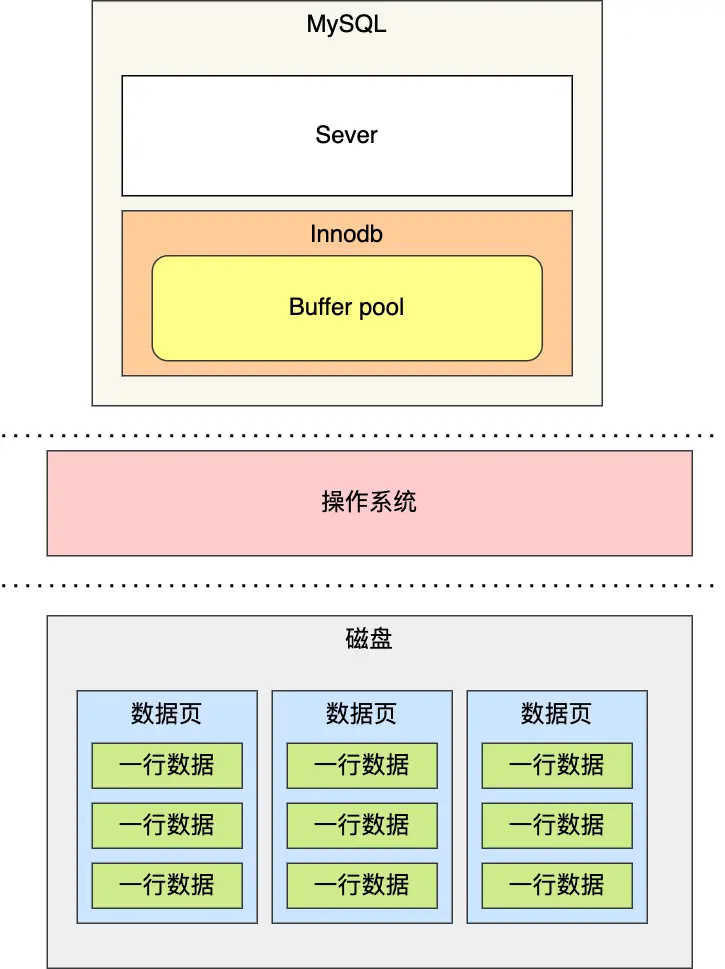
除了数据的读取保存在缓存中,对数据的修改也不是立即写入磁盘,而是先写到缓存后择机刷盘。所以 Buffer Pool 中包含脏数据(数据页中)和 undo 页
事务故障指事务未运行到既定的终点(没有commit或显式的rollback),例如对于支付系统若付款失败则需要回滚支付的操作,确保事务的一致性
系统故障指需要即时重启系统而造成的数据库故障,现象是修改内存中的修改未写到磁盘,写入磁盘的数据未必是完成的事务
介质故障指磁盘损坏造成的故障,需要全量迁移数据库数据
符合最优子结构的问题适合用动态规划
最优子结构 是指一个问题的最优解可以通过其子问题的最优解构造出来。换句话说,问题的最优解依赖于子问题的最优解。
例如要计算年级的最高分,可通过计算每个班级的最高分之后取最值得到
明确当前值需要通过哪些子结构通过哪些选择得到,用以确定dp数组是一维还是二维的
一级封锁协议
事务 T 在修改数据 W 之前必须先对其加 X 锁,直到事务结束才释放(读不加锁)
一级封锁协议可防止 丢失修改
不同事务对于同一范围内的数据进行增/删/改时需要锁确保在事务提交前只有一个事务能操作该数据
对于要修改的数据加锁(lock)
在当前读(区别于使用MVCC中ReadView的快照读)的场景下,在事务内不同时间对同一查询条件得到的查询结果不同
高层模块(稳定)不应该依赖于低层模块(变化),二者都应该依赖 于抽象(稳定)
抽象(稳定)不应该依赖于实现细节(变化),实现细节应该依赖于 抽象(稳定)
对扩展开放,对更改封闭
在转账场景中,A向B转账100元。转账过程需要保证的是要么转账成功,要么转账失败恢复到原始值(原子性 Atomicity);转账前后A与B账号的存款总数不变(一致性 Consistency);转账过程中A与B的其他转账操作不影响当前转账(隔离性 Isolation);转账成功则不可撤回(持久性 Durability)。所以引入事务(Transaction)的概念
使用B+树作为存储结构,非叶子结点存放索引,叶子节点才会存放实际数据(索引+记录)
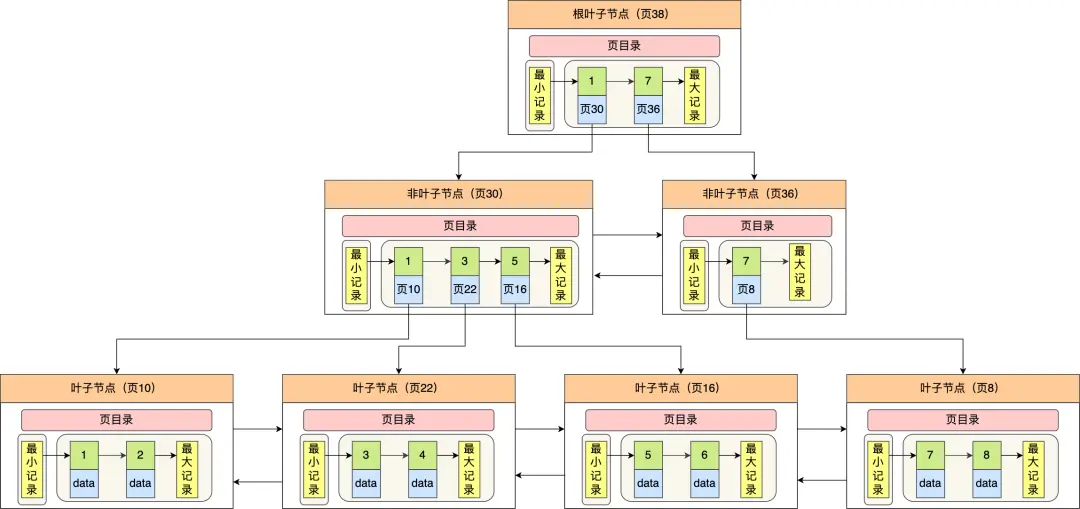
B+树与B树的对比如下
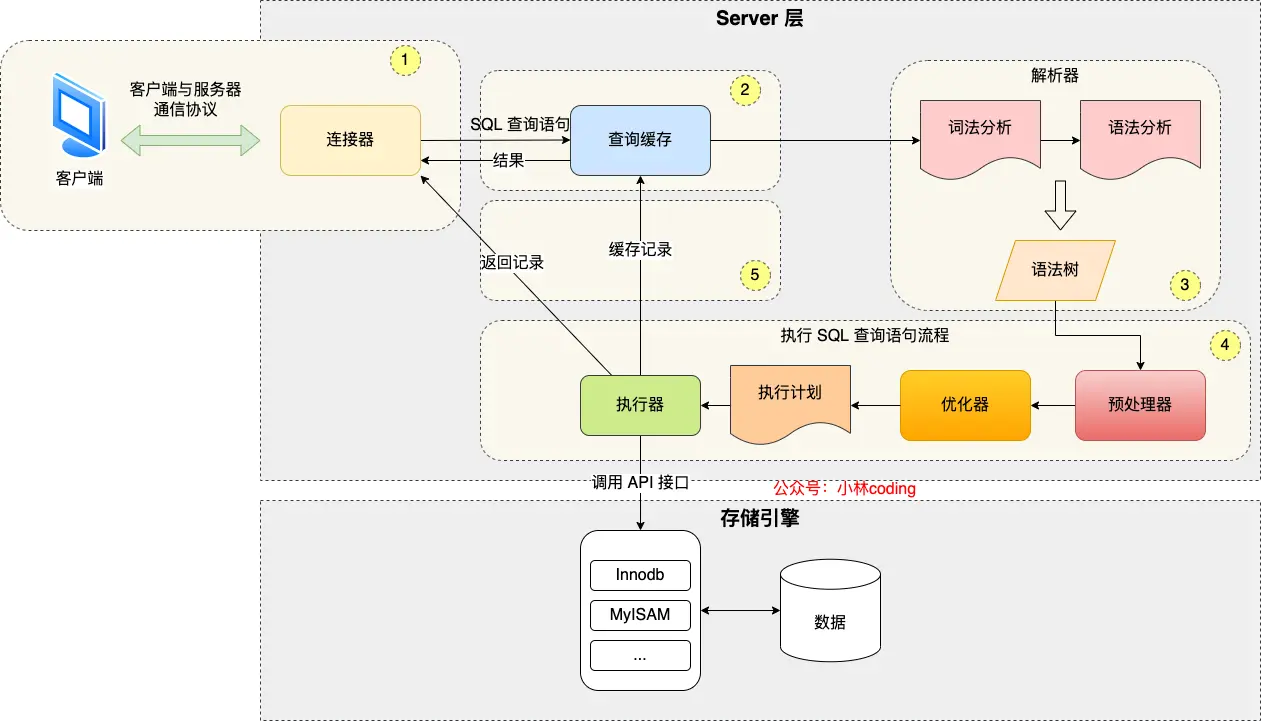
客户端通过TCP三次握手与数据库建立连接
如果 SQL 是查询语句(select 语句),MySQL 就会先去查询缓存( Query Cache )里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL 语句查询的结果。
解析器完成词法分析(根据输入的字符串识别出关键字)和语法分析(判断语句语法)
对于序列数据(文本,语音等),使用标准神经网络存在以下问题:
a<n>表示第n时间步最后一层隐藏层的输出,同时也是n+1时间步输入的一部分
y-hat<n>表示第n时间步的输出(通过与a<n>全连接得到)
vector<vector<int>> build_tree_with_table(int node_count,vector<vector<int>> prerequisites)
{
vector<vector<int>> graph(node_count);
for (int i=0;i<prerequisites.size();i++)
graph[prerequisites[i][0]].push_back(prerequisites[i][1]);
return graph;
}vector<vector<int>> build_tree_with_martix(int node_count,vector<vector<int>> prerequisites)
{
vector<vector<int>> graph(node_count,vector<int>(node_count,0));
for (int i=0;i<prerequisites.size();i++)
graph[prerequisites[i][0]][prerequisites[i][1]] = 1;
return graph;
}使用on_path判断当前访问的结点是否在当前访问列表中,如果在则表示有环
vector<vector<int>> path_lists;
vector<int> path;
vector<bool> on_path;
void traverse_dfs(vector<vector<int>> graph,int start)
{
if (src < 0 || src >= graph.size()) return;
if (on_path[start] == true)
return;
path.push_back(start);
on_path[start] = true;
path_lists.push_back(path);
for (int i=0;i<graph[start].size();i++)
traverse_dfs(graph, graph[start][i]);
path.pop_back();
on_path[start] = false;
}使用图的遍历DFS算法,if (on_path[start] == true)时给has_circle赋True
另外,使用了is_visited_list。假设现在以节点 2 为起点遍历所有可达的路径,最终发现没有环。
竖向堆叠起来的输入特征被称作神经网络的输入层(the input layer)。
神经网络的隐藏层(a hidden layer)。“隐藏”的含义是在训练集中,这些中间节点的真正数值是无法看到的。
输出层(the output layer)负责输出预测值。
对于回归或分类问题使用合适的模型,在本文中对于回归问题使用线形回归模型,对于分类问题使用Logistic回归模型
$$ J(w,b) = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f_{w,b}(x^{(i)}) - y^{(i)})^2 $$
$$ f_{w,b}(x^{(i)}) = wx^{(i)} + b \tag{2} $$
求解的关键在于画出决策树,并运用合理的剪枝条件。不要跳出此框架自己去想新写法,很容易漏解或者多解