线程池原理与实现
B站讲解视频:线程池原理与实现
线程池
线程池是什么
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。
B站讲解视频:线程池原理与实现
线程池(Thread Pool)是一种基于池化思想管理线程的工具,经常出现在多线程服务器中,如MySQL。
线程过多会带来额外的开销,其中包括创建销毁线程的开销、调度线程的开销等等,同时也降低了计算机的整体性能。线程池维护多个线程,等待监督管理者分配可并发执行的任务。这种做法,一方面避免了处理任务时创建销毁线程开销的代价,另一方面避免了线程数量膨胀导致的过分调度问题,保证了对内核的充分利用。

初始化流程主要包括从磁盘中加在持久化配置,将自己的状态设为 Follower
init:从磁盘中加在持久化配置,将自己的状态设为 Follower
becomeFollower:状态机切换为 Follower,执行 Follower 的处理流程
1 | int init() |
所有结点都可以响应客户端的读请求
Raft 是一个管理 replicated log 的算法
Raft 实现共识的机制
只有一个 Leader 的设计简化了 replicated log 的管理。例如,
Leader 可能会挂掉(fail)或从集群中失联(disconnected),这种情况下会选举一个新 Leader
在上学的时候,老师总会在班会课上让学霸分享经验,但真正按照他们的方法学下来也没什么用,而且他们说的还有很多矛盾,比方说:
根本就不知道该听谁的。
大学毕业后工作了几年,也遇到了很多优秀的人。原本以为在沟通中很难跟上大佬的思路。但接触下来发现他们平时也嘻嘻哈哈的,和普通人没什么两样。但是他们看上去不用费太多精力就能把事情做好。
我就在想,该怎么变得和他们一样优秀?怎么样去提高自己的学习能力?
每天去上班的路上我都在想这个事情,奇怪的是我好像从来没有思考过这个问题。在上学的时候,我关心的往往是题目,只想着怎么去把题目做对,但从来没有去反思过学习过程有没有问题。在应试教育下,我好像失去了一些思考的能力,每天按部就班得完成老师布置的作业,没有去关注过学习这件事本身。
就这样,我来来回回思考了一星期,得到的都是些模糊的印象,比如说要定期复习,上课认真听讲。然而这都是些感性认识,并不能成体系得去表达学习过程。这时,我接触到了两本书,《学习的逻辑》 和《认知觉醒》,看完后让我对它有了不一样的认识。
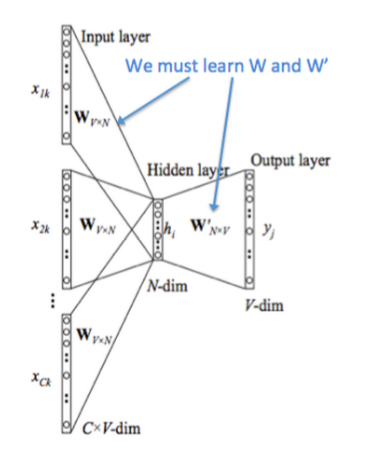
通过 one-hot 编码来表示单词有两个缺陷:
所以基于此提出了词嵌入技术。将一个维数为所有词的数量的高维空间(one-hot 形式表示的词)“嵌入”到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量
word2vec 是训练词嵌入的训练方法,其输入为 one-hot 编码,通过一个隐藏层输出单词(CBOW)或者上下文(Skip-gram)的one-hot 编码。其模型结构为 y=softmax(wx+b)
word2vec 的训练要求并不是要让输出的单词或上下文达到很高的准确度,而只需要确保模型在正确得收敛。word2vec 所要得到的其实是输入层到隐藏层的参数,即词向量
训练只有一层隐藏层,而且不包含激活函数。输入层—隐藏层的参数矩阵(编码器)即时one-hot到词向量的映射;隐藏层—输入层的参数矩阵(解码器)正好相反,数学上两者互逆。但实际上还是通过梯度下降训练,因为梯度下降时间复杂度为O(n),求逆则为O(n^3)
CBOW(Continuous Bag of Words):在给定上下文词(即目标词周围的词)的情况下,预测目标词
记得小学阅读课上,我在读一本悬疑小说并写到了读后感作业中,结果第二天就被老师批评,并以“开卷有益”这个成语来教导我说,你这种书以后少读读。当时,我就觉得老师这种说法一定是错的,但限于那时的表达能力和逻辑能力并不能给出完整的反驳,现写下此文以表述自己的想法。
“以后少读读”这句话一直在我脑海中,我不理解曾几何时,书之间也有了贵贱之分,难道读四大名著的就是好学生,读《福尔摩斯》的就是差学生吗?“开卷有益”指的是读书总有好处,并非告诉我们先对于书是否有益有了定性之后再去读。老师说的这些话显然是没有道理的。
那她又是出于什么原因这样说呢?说到底,四个字,功利主义。什么书对于学习有帮助那就是有益的,没帮助就是浪费时间。我们中的很多人从小被灌输这样一个观念:只有努力学习才能上好大学,只有上好大学才能找到好工作,才能有幸福的生活。曾经我也认为这句话是对的,为了以后能开心地生活现在必须努力学习。但真的是这样吗?从学校到工作到生话并非完全是后者依赖前者的先序关系,其中某一环节的丢失并不一定能影响到之后的生活。这种观点只是指出人生中几个重要结点,并对每一个结点提出要求。上了好大学能就能仕途一帆风顺,有了好工作真能天天开开心心享受生活?不尽然。
前段时间,“鸡娃”一度成为社会热点问题,家长给孩子报了各种补课班,兴趣班,以求孩子能领先他人一步。我想,他们也许都是上文观点的拥趸,生怕自己孩子因为没补课而落后其他同学。其实,我小时候也是个“鸡娃”,从幼儿园开始补课直到高中毕业,周末只是换了个地方上课。现在看来,报那么多班其实未必有用,现在的我也只是刚从普通大学毕业,过着平淡的生话。每个人学习能力不同,那假设补课班是有用的,能让所有上课的孩子成绩提升,考上好大学,但那之后呢,补课班除了能培养出优秀的做题家外并不会给孩子带来什么。
好大学并不是人生的终点,拥有幸福快乐的人生也不是名校生的特权,否则怎么会有某大学投毒案,某大学弑母案呢?这一切的一切都是功利主义在作祟,他们认为人生只需要为那几个重要结点去准备就行了,达到目的则视为成功,在他们的眼中,世界是线性的,必须要完成一个个小目标,追求利益最大化,否则就是失败。但他们不知道的是人生并不是一蹴而就的,阶段性的成功并不意味着什么。事物之间也在不断变化发展,幸福的人生并不是公式化的结果,在这之中更重要的是我们对为人处世的态度,以及对于个人,社会,以及世界的看法,这会贯穿人的一生,而非学校,工作等短暂的光环。
冯友兰先生将人生分为四种境界:自然镜界,功利境界,道德境界和天地境界。你我皆为凡人,虽难以达到“敬天爱人,天人合一”,但也不应在功利境界一直徘徊,为了眼前的利益患得患失。“开卷”何必“有益”,看自己想看的书,做自己想做的事,何必要按照公式走完自己的人生呢。
对于序列数据(文本,语音等),使用标准神经网络存在以下问题:
a<n>表示第n时间步最后一层隐藏层的输出,同时也是n+1时间步输入的一部分
y-hat<n>表示第n时间步的输出(通过与a<n>全连接得到)
Waa表示a<n>对第n+1时间步输入的权重
Wax表示x<n>对第n时间步输入的权重
每个时间步是相同的网络(即同样的参数),输入数据序列有多大则有几个时间步
| 类型 | 含义 | 最小尺寸 |
|---|---|---|
| bool | 布尔 | 未定义 |
| char | 字符 | 8位 |
| short | 短整型 | 16位 |
| int | 整型 | 16位 |
| long | 长整型 | 32位 |
| long long | 长整型 | 64位 |
| float | 单精度浮点数 | 6位有效数字 |
| double | 双精度浮点数 | 10位有效数字 |
| long double | 扩展精度浮点数 | 10位有效数字 |
int值时,int会被转换为无符号数变量声明(declaration)定义了变量的类型和名字,定义(definition)在声明外还申请存储空间
如果只想声明,可在变量名前添加关键字extern
变量只能被定义一次,但是可以多次声明
const对象一经创建后其值不能再改变,所以const对象必须初始化
1 | const int i = 1; |
默认情况下,const对象仅在文件内有效。若需在不同文件使用同一const对象,则const变量不管是声明还是定义都添加extern关键字,这样只需定义一次就可以了
1 | extern const int bufSize; |
用于声明引用的const都是底层const,引用本身已默认为顶层const(无法改变指向)
const型变量只能由const型引用(底层const)
不能把普通引用绑定到字面值上,需用底层const
非const型变量可以由const型引用,但不可通过引用修改被引用变量值
读写string对象
1 | string s; |
当把string对象和字符(串)字面值混在一条语句时,必须确保加法运算符(+)两侧的运算对象至少一个是string
vector是模板而非类型
1 | vector<T> v1; |
凡是使用了迭代器的循环体,都不要向迭代器所属的容器添加元素
理解复杂的数组声明(P102-103)